「llama2.c」を試したときに「TinyStories(小さな物語)」というデータセットの存在に興味を持ったので少し調べてみました。
タイトルは「TinyStories: How Small Can Language Models Be and Still Speak Coherent English?」。著者はRonen Eldan, Yuanzhi Li (Microsoft Rsearch)、2023年5月の論文です。
論文要旨(日本語訳)
言語モデル(LM)は自然言語処理のための強力なツールであるが、パラメータが小さい場合、首尾一貫した流暢な文章を生成するのに苦労することが多い。GPT-Neo(small)やGPT-2(small)のような125M程度のパラメータを持つモデルは、広範な学習を行っても、数語以上の首尾一貫した一貫性のある英文を生成することはほとんどできない。このことは、首尾一貫した英文を生成する能力の出現は、より大きなスケール(数億以上のパラメータを持つ)や複雑なアーキテクチャ(何層もの大域的な注意を持つ)においてのみ発生するのかという疑問を提起する。本研究では、GPT-3.5とGPT-4によって生成された、典型的な3~4歳児が通常理解する単語のみを含む短い物語の合成データセットであるTinyStoriesを紹介する。TinyStoriesを用いることで、最先端のモデルよりもはるかに小さい(総パラメータが1000万以下)、あるいははるかに単純なアーキテクチャ(変換ブロックが1つしかない)を持つLMを学習・評価できることを示す。また、言語モデルの評価のための新しいパラダイムも紹介する: GPT-4を使って、これらのモデルによって生成されたコンテンツを、あたかも生徒が書いた物語を(人間の)教師が採点するかのように採点する枠組みを提案する。この新しいパラダイムは、モデルの出力がしばしば非常に構造的であることを要求する標準的なベンチマークの欠点を克服し、さらに、文法、創造性、一貫性などのさまざまな能力に対するスコアを提供することで、モデルに対する多次元的なスコアを提供する。
メモ
-
従来、10Mパラメータ以下の小さく単純な構造の言語モデルでは首尾一貫したテキストを生成するのが難しいとされていたが、データセットの工夫により流暢なテキスト生成も可能であることを示した。
-
具体的には、幼児レベルの限られた語彙を使い簡単な構造で書かれた短い物語文(TinyStories)をGPT3.5で生成し、これをデータセットとして学習に用いた。
-
TinyStoriesで学習したモデルの出力は、GPT-4により評価した。文法的に正しい文章を出力する能力はかなり小さなモデルでも観察され、文脈整合性や創造性の能力も順次発現する。
-
小規模モデルでも、文法や整合性は大規模モデルに近い水準に到達するが、創造性においては比較的大きな差が残る。
-
結論として、小さなモデルが一貫した文章を生成できないのはモデルにその能力が無いからではなく、一般的な学習データが語彙や内容的多様性の点で複雑すぎるからだろうという指摘。
雑感
-
肝心のTinyStoriesデータセットの物語自体が(かわいらしいが)面白くはないというのが気になってしまう。論文の主旨から言えばあまり重要ではないのだろうが、物語の面白さをより的確に評価できたら嬉しい。
-
GPT-4であっても、長い文章で文脈的整合性の維持するのは現状難しく、プロンプトで介入しながら分割的に生成せざるをえない。「シンプルで定型的なデータセットで学習することで、より質の高いテキストを生成できる」という本論文の知見は、より大型の言語モデルの学習自体にも敷衍できる?例えば、SFなど特定ジャンルの短編小説を構造化したデータセットで訓練すれば、短編SFに特化した高品質の出力が期待できるのでは。
-
この研究では、データセットの生成時に、物語の多様性を維持するためにランダムなキーワードを指定している。言語モデルは「同じようなテキスト」を出力しがちなので、温度を上げるだけでなくプロンプトを工夫する必要がある。
-
GPT-4によるテキスト評価の個所で、GPT-4自身が出力したテキストをGPT-4に評価させているが、Creativity(8.26/10)やPlot(8.21/10)の自己評価が辛めなのが興味深い。GPT-4のような高性能モデルでも、評価・要約のような抽象化タスクは得意だが、創作のような具体化タスクは難しい。よって、アウトプットがモデル自身が納得するレベルには至らない。評価者/創作者としての能力ギャップが常に存在する。これは人間も同じことだけれど。
以下は、本文の抄訳(DeepLとChatGPTによる)。
---
1. イントロダクション
例えば、GPT-Neo(小)やGPT-2(小)のような125M程度のパラメータを持つモデルは、Pile [9]、CommonCrawl [1]、CC-100 [31]のような大規模なコーパスで広範な学習を行っても、数語以上の一貫性のあるテキストを生成することはほとんどできない。これらのモデルは、しばしば支離滅裂、反復的、または無意味な文章を生成し、明確なトピックや段落間の論理構造を維持することができない[12]。このことは、首尾一貫した英語を話す能力の出現には、大規模なモデル(数億以上のパラメータを持つ)と複雑なアーキテクチャ(グローバルな注意を何層にも重ねる)が必要なのではないかという疑問を提起している。
しかし、小規模な言語モデル(SLM)が首尾一貫したテキストを作成できないのは、自然言語の本質的な複雑さのせいなのか、それとも学習に使用するコーパスの過剰な広さと多様性のせいなのかは、今のところ明らかになっていない。例えば、ウィキペディアでモデルを学習させる場合、英語の話し方を教えるだけでなく、さまざまなドメインや分野から膨大な量の事実や概念をエンコードし、検索する方法も教えることになる。
このことは、文法、語彙、事実、推論といった自然言語の本質的な要素を保持しながらも、その幅と多様性という点でははるかに小さく、より洗練されたデータセットを設計できないかという疑問を提起している。
本論文では、GPT-3.5とGPT-4によって生成された、3~4歳児が一般的に理解できる単語のみを含む短編小説の合成データセットであるTinyStoriesを紹介する。TinyStoriesは、自然言語の本質を捉えつつ、その幅と多様性を減らすように設計されている。各ストーリーは、単純な筋書きと一貫したテーマに沿った2-3段落で構成され、データセット全体は、3-4歳児の語彙と事実知識の基盤にまたがることを目指している。
このデータセットに基づき、本論文はいくつかの主要な貢献を行う。
- TinyStoriesを使用して、最先端のモデルよりもはるかに小さい(256の埋め込み次元で1,000万以下のパラメータ)、またははるかに単純なアーキテクチャ(1つの変換ブロックのみ)を持つ小規模な言語モデル(SLM)
を訓練および評価できることを示すことである。さらに、モデルのサイズが小さいにもかかわらず、推論能力、一般的な事実の知識、特定の命令に従う能力の出現が観察される。
- GPT-4を使用した言語モデル評価のための新しいパラダイムを導入し、標準的なベンチマークの制限の多くを克服する。
- TinyStories上の生成モデルの学習は、通常1GPUで1日以内に完了するが、スケーリング則、幅と深さのトレードオフなど、LLMで観察されるものと類似した多くの挙動を示すことを示す。限られた計算資源でも、ハイパーパラメータ、アーキテクチャ、学習方法の違いがモデルの性能と品質に及ぼす影響を調べるための広範な実験を行うことができる。
- 訓練された小規模な言語モデル(SLM)は、より大きなSLMよりも実質的に解釈可能であることを示す。ニューロンの数が少ない、あるいは層の数が少ないモデルの場合、注意ヘッドとMLPニューロンの両方が意味のある機能を持つことが観察される: アテンションヘッドは非常に明確なアテンションパターンを生成し、ローカルヘッドとセマンティックヘッドは明確に分離される。我々は、モデルの注意マップと活性化マップを視覚化し、分析することで、それらがどのように生成プロセスとストーリー内容に関連しているかを示す。
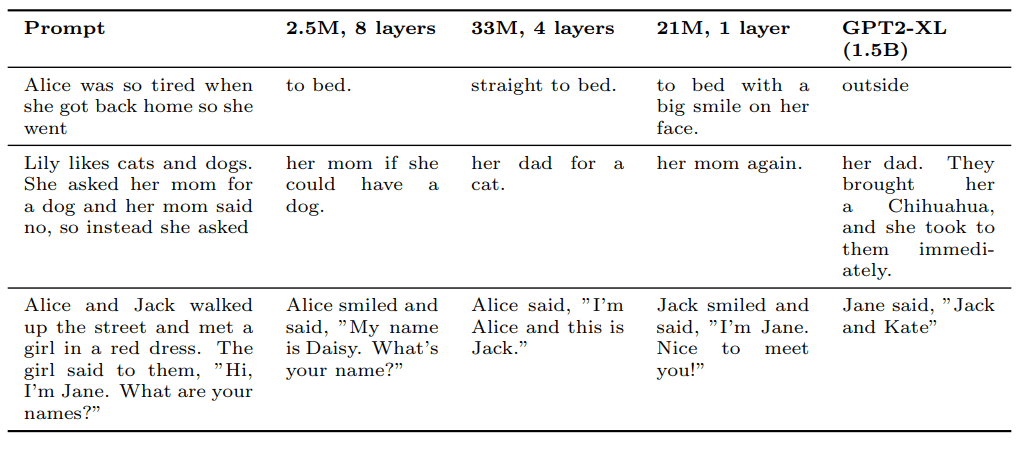
(上記の図について)この論文中で示された多くの他の例とともに、これらの補完は非常に小さなモデル(2.5M)やトランスフォーマー層が1つしかないモデルでも事実知識を獲得できること、やや大きなモデルならある程度の推論能力を表現できることを示す。GPT2-XLのパフォーマンスとの比較から、TinyStoriesデータセットは、大規模な言語コーパスでトレーニングされたモデルと比較して、これらの能力がはるかに小さなスケールで現れることを証明できる。
2. TinyStoriesデータセットの説明
上記のように、TinyStoriesデータセットのアイデアは、文法、語彙、事実、推論など、自然言語に見られるすべての定性的要素を結合することであり、同時により小さく、多様性が少なく、内容についてより制限されたコーパスを持つ。これを実現する自然な方法は、幼い子供たちは成人よりもはるかに少ない言語への露出で前述の知的能力を質的に獲得するという事実を利用することである。
このため、OpenAIの最新のテキスト生成モデル(GPT-3.5およびGPT-4)に頼り、指示に従って大量の合成コンテンツを生成できるようにする。特に、モデルに対して、典型的な3歳児が理解できる語彙しか使用しないコンテンツを生成するように指示する。コンテンツは英語の短編小説の形式に制限します。大規模な言語モデルをトレーニングデータを生成するために使用する上での主な課題は、十分に多様なデータセットを生成することです。モデルにストーリーを生成させると、生成の温度が高く設定されていても非常に反復的なデータセットが生成され、子供たちが理解する言語に対する比較的「理解」を持つ言語モデルをトレーニングするために必要な多様性から非常に遠いものになる。
多様なデータセットを作成する問題に対処するため、名詞、動詞、形容詞に分けられた典型的な3〜4歳児の語彙を模倣する約1500の基本単語からなる語彙を収集した。各生成において、ランダムに3つの単語(動詞、名詞、形容詞の各1つ)が選択される。モデルには、これらのランダムな単語を物語にどのように組み合わせるかを指示する。以下で主張するように、これによってデータセットの多様性が大幅に増加し、物語が子供たちが馴染みのある語彙全体をカバーし、異なる概念を組み合わせるための豊富な手段を含むようになります。さらに、物語が持つ可能性のある特徴(対話、筋書きの転換、悪い結末、道徳的価値など)のリストを作成した。各物語について、これらの特徴のランダムなサブセットを生成し、物語がこれらの特徴を持つことを追加の要件としてモデルに指示する。
以下はGPT-3.5によって生成されたプロンプトとストーリーを含むサンプルである。
プロンプト:3歳の子供が理解できる非常にシンプルな言葉だけを使って、短いストーリー(3-5パラグラフ)を書いてください。「decorate」という動詞、「thunder」という名詞、「ancient」という形容詞を使用する必要があります。ストーリーには以下の特徴が必要です:ストーリーには少なくとも1つの対話が含まれていること、ストーリーは悪い結末を迎えることがあることを覚えておいてください。
(Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would likely understand. The story should use the verb ”decorate”, the noun ”thunder” and the adjective ”ancient”. The story should have the following features: the story should contain at least one dialogue, the story has a bad ending. Remember to only use simple words!)
アウトプット:昔々、古い家にリリーという女の子が住んでいました。彼女は美しい物で彼女の部屋を飾るのが好きでした。ある日、彼女は屋根裏部屋で大きな箱を見つけました。彼女はそれを開けて、多くの輝く装飾品を見ました。リリーは非常に嬉しくなり、それらを彼女の部屋で使うことに決めました。
リリーが部屋を飾っていると、外の空が暗くなりました。大きな雷の音が鳴り響き、リリーは怖くなりました。彼女は母親のところに走って行って、「お母さん、雷がすごい!」と言いました。彼女の母親は彼女を抱きしめて、「心配しないで、すぐに過ぎますよ。」と言いました。
しかし、雷は止まりませんでした。ますます大きくなり、古い家は揺れ始めました。突然、屋根が落ちて美しい装飾品が台無しになりました。リリーは悲しくなりました。彼女の部屋はもうきれいではありませんでした。おしまい。
自然言語生成のもう一つの課題は、与えられた指示や制約に沿って、つながりがあり、関連性があり、一貫性のあるテキストを生成することです。コンテンツの作成だけでなく、指示に従う能力を評価するために、TinyStoriesのバリアントであるTinyStories-Instructを作成しました。このバリアントでは、各ストーリーの前に対応する指示のセットが付属しています。指示には以下の4つのタイプがあります。
・ストーリーに含めるべき単語のリスト。
・ストーリーのどこかに現れるべき文。
・特徴のリスト(例:対話、悪い結末、道徳的価値、プロットの転換点、前兆、衝突)。
・ストーリーの短い要約(1-2行)。
このデータセットの各エントリーには、これらの指示のランダムなサブセットが続いてストーリー自体が続きます。このように、このデータセットで訓練されたモデルが与えられた場合、任意の指示を反映するプロンプトを作成し、モデルを使用して対応するストーリーを生成することができます。以下は、データセットからの例です。
・要約:リリーとティミーは一緒に砂の城を作り妥協を学びますが、突風で壊れてしまいます。彼らは壊れた砂の城に美しさを見出し、幸せに蝶と遊びます。
・特徴:対話、前兆、転換点
・指定文:「ある日、彼女は公園に行って美しい蝶を見ました。」
・単語:論争、ネットワーク、美しい
・ストーリー:昔々、リリーという小さな女の子がいました。彼女はおもちゃと友達と一緒に遊ぶのが大好きでした。ある日、彼女は公園に行って美しい蝶を見ました。彼女はそれを捕まえようとしましたが、飛んでしまいました。リリーの友達ティミーが彼女と一緒に遊びに来ました。砂の城を作ることに決めましたが、リリーは高く作り、ティミーは広く作りたいと思っていました。しばらく論争しましたが、最終的に高くも広くもすることに合意しました。砂の城を作っていると、一緒に働いているアリのグループを見つけました。彼らはトンネルのネットワークを作っていることに気づきました。突然、突風が吹いて砂の城を倒しました。彼らは悲しかったが、蝶をもう一度見つけました。それは彼らの砂の城の残骸に着陸し、壊れた状態でも美しいことに気づきました。彼らはにっこり笑って幸せに一緒に遊びました。
TinyStories-Instructは次のように作成されました:元のデータセットの各ストーリーには、作成に使用された単語と特徴のリストがすでにありました。さらに、GPT-3.5を使用してストーリーの短い要約を作成し、各ストーリーからランダムな文(最初の文以外のどの文でも可能)を抽出しました。その後、これらのランダムなサブセットから指示を組み合わせて、ストーリー自体が続きます。
3. GPT-Eval:TinyStoriesで訓練されたモデルの評価フレームワーク
通常、言語モデルの評価の一般的なパラダイムは、モデルの出力が与えられた答えと一致する必要があるタスクの形式で構成される構造化された評価データセットに依存しています。しかし、この文脈ではより適切だと考えられる新しいパラダイムを導入します。
私たちは、既存の大規模言語モデルを利用して、モデルが生成したストーリーを評価することができます。手動で作成された約50のプロンプトから作成されるデータセットからストーリーの開始部分を提供し、モデルに補完を生成させ、そのストーリーの開始部分とモデルによる補完をGPT-4に提供し、文法、創造性、ストーリーの開始部分との整合性の点で補完課題を評価するように求めます。プロンプトには通常、完成させる必要のある部分的な文が含まれており、文が切り取られた状態で文法的に非自明な課題を完了するように書き込むように試みました。
例えば、上記の例にあるストーリーを取り上げ、”loud”の後にそれを切り取りました。 約28Mのパラメータを持つモデルを使用して、上記のストーリーの補完を生成しました(生成部分は【】で強調表示されています)。次に、GPT-4に口頭評価を提供し、その後、補完の評価を求めました。以下は、GPT-4が生成した部分をイタリック体で示したインタラクションの記録です。
プロンプト:この練習では、生徒に物語の始まりが与えられます。生徒はそれを完全な物語に完成させる必要があります。この練習は生徒の言語能力と創造性をテストします。シンボル「***」は指定された開始部分と生徒の完成部分の区切りを示しています:
「昔々、古い家にリリーという女の子が住んでいました。彼女はかわいいもので自分の部屋を飾るのが大好きでした。ある日、彼女は屋根裏部屋で大きな箱を見つけました。彼女はそれを開けて、たくさんのきらめく装飾品を見ました。リリーはとても嬉しく、それらを自分の部屋で使うことに決めました。
リリーが部屋を飾っていると、外の空が暗くなりました。大きな***
【雷鳴と明るい閃光がありました。リリーは少し怖くなりましたが、勇敢である必要があることを知っていました。彼女は両親に話し、彼らは外に出て何が起こっているのか見に行きました。
外に出ると、大きな嵐が来ていました。風が強く吹き、雨が降り注いでいました。リリーと彼女の両親は安全な場所を探さなければなりませんでした。大きな木を見つけて、その下に隠れました。嵐は過ぎ去り、再び太陽が出ました。リリーと彼女の両親は、古い家の中で安全で暖かく過ごしました。】
評価(GPT-4):生徒によるストーリーの完成部分は、大部分がストーリーの開始部分と整合しています。リリーと彼女の家族に焦点を当て、区切りのある文が正しく完成されています。ただし、生徒の追加部分は、屋根裏で見つかった輝く装飾品を完全に統合していませんでした。文法は一般的に正確ですが、いくつかの小さなエラーがあります。全体的には、生徒のストーリーの完成部分は、適切な言語能力と創造性を示していますが、輝く装飾品の統合と文法の改善が必要です。
プロンプト:次に、生徒の完成部分を文法、創造性、ストーリーの開始部分との整合性、プロットが意味をなしているかについて評価し、生徒の年齢層を推測してください。年齢層の選択肢は、A:3歳以下、B:4-5歳、C:6-7歳、D:8-9歳、E:10-12歳、F:13-16歳です。
評価(GPT-4):文法:8/10、創造性:7/10、整合性:7/10、年齢層:E(10-12歳)
TinyStories-Instructで訓練されたモデルの完全な評価を行うために、手動で構築された評価セットの各プロンプトについて、訓練されたモデルを使用して温度1で10個の補完を生成します。すべての補完のGPT-4評価スコアを平均します。図3は、トレーニングが進むにつれて、いくつかのモデルサイズのトレーニングと評価の損失とともに、異なるスコアの進化の例を示しています。図4は、一定数のトレーニングステップ後に、異なるモデルサイズとアーキテクチャで異なるスコアがどのように変化するかを示しています。
TinyStories-Instructで訓練されたモデルの評価方法は、GPT-4に依存しています。評価データセットには、50の異なるストーリーを作成するための指示が含まれており(これらがトレーニングセットから切り離されていることを確認しました)、スコアリングフェーズでは、GPT-4に指示と生成されたストーリーの両方を提供します。GPT-4に、ストーリーが与えられた指示を正確に反映している程度に基づいて整合性スコアを割り当てるように求めます。さらに、プロットのカテゴリを追加し、プロットが整合している程度を反映するようにしました。図5は、私たちのモデルによるストーリーの生成とGPT-4による評価を組み合わせたパイプライン全体を示しています。異なるサイズのモデルに割り当てられたスコアは、図4の表の右側に示されています。
評価フレームワークには、以下のようないくつかのスコアリングカテゴリが含まれます。
文法スコア:生成されたストーリーが文法的に正しいかどうかを評価します。生成された文が文法的に正しくない場合、スコアは低くなります。
創造性スコア:生成されたストーリーが創造的かどうかを評価します。ストーリーに新しいアイデアや展開が含まれている場合、スコアは高くなります。
整合性スコア:生成されたストーリーが与えられた指示と整合しているかどうかを評価します。ストーリーが指示に沿って進んでいる場合、スコアは高くなります。
プロットスコア:生成されたストーリーのプロットが意味をなしているかどうかを評価します。ストーリーが意味のあるプロットを持っている場合、スコアは高くなります。
年齢層推定:生成されたストーリーの内容とスコアから、対象読者の年齢層を推定します。
これらのカテゴリを使用して、TinyStoriesで訓練されたモデルの性能を評価することができます。このフレームワークは、様々な言語モデルの評価にも適用することができます。ただし、モデルのスコアリングと比較のために、より多くの評価データセットが必要になる場合があります。

提案された評価方法は、より詳細なモデルの評価を行う方法を提供することにより、モデルのサイズやアーキテクチャによる異なる能力の依存関係についての結論を導き出すことができます。評価スコアはすべて評価損失の低下に伴い一貫して増加していますが、結果をより注意深く調べると、以下のことがわかります。
・図3は、文法的な面で、浅いモデルが内容の整合性を維持するに比べて優れていることを示しており、モデルの深さは、文法的に正しい言語を生成するよりも、内容に整合するためにより重要であることを示しています(次のセクションでこれを裏付ける追加証拠を提供します)。
・同じ図では、文法のスコアが他の2つのスコアよりも早い段階で横ばいになることがわかります。さらに、表4では、文法は比較的小さなモデルでも習得できるが、整合性と創造性はより大きなサイズでのみ現れることが示されています。
・表4は、モデルの隠れ層のサイズが64から128に増加すると、ストーリーの最初の部分に整合する完了形式を生成する能力が現れることを示唆しています。
・また、TinyStoriesで訓練された最大のモデル(約80Mのパラメータを持つ)は、文法と整合性の点でほぼ完璧なスコアを達成しています。ただし、創造性の点ではGPT-4の能力には及ばず、創造性は、文法と整合性に比べて、モデルとデータセットのサイズが大きくなるにつれてより大きく改善されることを示唆しています。
・表4の右側の列は、1層しかないモデルが指示の追跡に苦戦していることを示しています(おそらくグローバルアテンションに大きく依存しています)、2層であれば、ある程度の指示の追跡に十分であることがわかります。また、「Instruct」と「Plot」のスコアを比較すると、指示に従う品質は層の数によってより強く依存し、プロットの整合性には隠れ層の次元がより重要であることがわかります。
4. TinyStoriesでトレーニングされた小さなモデルのパフォーマンス
このセクションでは、TinyStoriesによって生成された非常に小さなサイズのモデルが、意味のある言語を生成し、常識的な知識と推論能力を一定程度示すことができることを示す初期的な例をいくつか示します。また、生成されたコンテンツがただ「覚えられた」コンテンツを出力するだけではないことを証明するための証拠も提供します。
このセクション全体で、約1M〜35Mパラメータを持ち、レイヤー数が1〜8のいくつかのモデルアーキテクチャを取り扱います。これらのすべてのモデルは、最大30時間以内に単一のV100 GPUでトレーニングできます。
(TinyStoriesでトレーニングされた)非常に小さなモデルの能力を垣間見るために、いくつかの例を調べてみましょう。最初に、トレーニングセットから取得した以下のストーリーを観察します。
<サラとベンは雪の中で遊んでいます。彼らは帽子とスカーフをつけた大きな雪だるまを作りました。彼らは幸せで笑います。しかし、大きな犬がやってきました。犬は怒って吠えます。彼は雪だるまに向かって走り、帽子を噛みます。サラとベンは怖くなって泣きます。「犬、行って!私たちの雪だるまを放っておいて!」サラが叫びます。しかし、犬は聞きません。彼はスカーフと雪だるまの鼻を噛みます。彼は頭を振って、雪だるまを倒します。
サラと【ベンは家に走ります。彼らはドアをバタンと閉めて、鍵をかけます。彼らは安全で、お互いを抱きしめます。「お母さん、お母さん、大きな犬が私たちの雪だるまを壊しました!」ベンが言います。母親がやってきて、彼らを抱きしめます。彼女はごめんなさいと言って、キスをします。「心配しないで、私たちは明日別の雪だるまを作ることができます。でも今は温かくして、ホットチョコレートを飲んで、食べて。あなたたちは寒くて、濡れています。」彼女は彼らをキッチンに連れて行き、ホットチョコレートを作ります。彼女は彼らにクッキーとマシュマロを与えます。彼女は彼らに飲んで、食べてと言います。サラが最初に飲み、次にベン。ベンが最初に食べ、次にサラ。彼らは気分が良くなり、笑います。彼らはお母さんに感謝し、彼女たちが彼女を愛していることを伝えます。彼らは大きな犬と寒さから逃れ、幸せで暖かいです。】>
次に、【】括弧内の部分を取り除いたストーリーの中央部分を切り取り、いくつかの異なるモデルで代替の結末を生成します。まずは、約15億のパラメータを持つGPT2-XLによって生成された補完からベースラインを設定します。
<...サラと【ベンは泣きながら、雪の中の雪だるまを見つめます。ベンは何かをするように頼みます。サラは小さな赤いボタンを握りしめます。雪だるまは毛皮で覆われています。それは赤い毛皮です。それは本物の毛です。それは本物の雪だるまです。彼らが以前作ったものとまったく同じように見えます。ベンは大きな笑顔を浮かべています。彼が作った顔を見て、歩きながら目をキスします。彼は生きていることに幸せです。彼は彼がやろうとしていたことをした。彼は世界を救った。】>
次に、約250万のパラメータを持つTinyStoriesでトレーニングされたモデルによる生成を提供します。
<…サラと【ベンは非常に悲しく、怒っています。彼らは泣き、犬に向かって叫びます。「悪い犬!悪い犬!行って!」ベンが言います。「悪い犬!私たちを放っておいて!」サラが言います。犬は去りません。彼は尻尾を振って、彼らの顔を舐めます。サラとベンは犬をかわいそうに思います。彼らは彼を幸せにしたいです。「彼のために新しい雪だるまを作ることができるかもしれない」とサラは言います。「かもしれない」とベンは言います。彼らは犬を抱きしめ、彼に名前をつけます。犬は尻尾を振って、彼らの顔を舐めます。「彼は私たちが好きかもしれない」とサラは言います。「彼は私たちが好きかもしれない」とベンは言います。犬は尻尾を振って、彼らの顔を舐めます。彼は幸せで友好的です。】>
まず第一に、上記の生成がストーリーのオリジナルの結末と非常に異なることに注意する必要があります。これは、単に記憶されたものではないことを示す最初の証拠であり、後でより詳細に議論します。また、生成されたコンテンツがプロット、キャラクター、およびイベントに関して始めと一貫していることも見て取れます。ほぼ1000倍も小さいモデルのサイズであるにもかかわらず、この継続は、GPT2-XLによる継続部分の生成よりも高い品質を持っていると主張できます。
5. 解釈可能性
深層ニューラルネットワークおよび特に言語モデルの内部機能を理解することは、この研究分野において大きな課題です。たとえば、ニューラルネットワークの特定のコンポーネントに特定の機能を割り当てることはしばしば困難です。これは、人間が設計したプログラムに基づく直感に反して、ネットワークのコンポーネントが明確な役割を持たない場合があり、代わりに複雑で複雑な方法で相互作用するためです。このセクションでは、TinyStoriesでより小さなモデルをトレーニングすることが、より高い解釈性につながることを示す、一部の予備的な証拠を提示します。つまり、ネットワークがサイズに制限されている場合、内部メカニズムについていくつかの洞察を得ることができる可能性があることを示唆しています。私たちは、モデルの2つの側面に焦点を当てます:アテンションヘッドとMLPのニューロン。本論文の主要な焦点ではないため、このセクションは必ずしも網羅的なものではなく、より確定的な結論に至るためには、さらに多くの作業が必要です。むしろ、将来の研究を促すために、予備的な証拠をいくつか提示するだけです。
アテンションヘッド。アテンションヘッドの研究では、われわれは非常に浅いモデル(トランスフォーマーブロックが1つしかない)をトレーニングできたことを利用します。このモデルは意味のあるテキストを生成することができます。モデルには1つのレイヤーしかないため、アテンションヘッドは出力トークンの生成に直接責任があるため、より深層のモデルよりも解釈可能な機能を持つ可能性があります。我々は、Voitaら[30]の方法を用いてヘッドのアテンションパターンを分析し、位置、構文、または意味などの異なるタイプに分類します。また、Clarkら[6]の方法を用いて、ヘッドのアテンションマップを可視化し、具体的な例における振る舞いを調べます。
私たちの調査結果は、アテンションヘッドが、前の単語、文の主語、文の終わり、またはストーリーの主要なトピックに注意を払うなど、多様で意味のある機能を示すことを示唆しています。また、名詞、動詞、句読点などの特定のタイプの単語を生成するために特化したアテンションヘッドがあることも観察されました。これらの結果は、アテンションヘッドが異なる言語的タスクを実行し、ストーリーの異なる側面を捉えて学習していることを示唆しています。
MLPのニューロン。また、より小さなモデルでは、MLPの一部のニューロンが人間によって解釈可能な役割を持つことを示す初期的な証拠を示します。私たちは、それぞれのニューロンに対して、最も影響力があるトークンを特定するために、[18]に類似した方法を使用します。私たちは、一部のニューロンが、文の特定の役割(主語や動作など)や物語の紹介など、特定の役割を持つ単語で活性化されることを発見しました。これらの調査結果は、MLPのニューロンが、異なる意味やスタイルの情報をエンコードし、生成プロセスに影響を与えることを学習していることを示唆しています。
6. TinyStoriesを用いたNLPのアーキテクチャとハイパーパラメータの探索
大規模言語モデル(LLM)を開発する上での主要な課題の1つは、トレーニングにかかる高い計算コストです。LLMの最適なアーキテクチャ、トレーニングアルゴリズム、およびハイパーパラメータを見つけるには、多くのリソースと実験が必要です。そのため、LLMの基本的な機能を捉えることができるより小さくシンプルなデータセットがあると便利であり、異なる設計選択が性能にどのように影響するかを研究することができます。TinyStoriesは、このようなデータセットの1つであり、最先端のモデルよりも桁違いに小さいLLMをトレーニングおよび評価できるため、一貫したテキストを生成する基本的な機能を持っています。
本研究では、TinyStoriesをNLPの実験用テストベッドとして利用するための最初のステップを踏み出します。小さなモデルが一部の面でLLMと似たパターンを示すことを示します。特に、以下の2つの質問について調査します。トレーニングFLOPsに対するモデルのサイズと学習予算のバランス、および与えられたモデルの幅と深さに対する注意ヘッドの数の選択です。
モデルサイズ対トレーニングFLOPs。トレーニングFLOPsの量が固定された場合、モデルサイズとトレーニングステップ数の間にトレードオフがあります(総FLOPsは両方の乗算です)。過去の研究[16、11]は、LLMに対してモデルサイズと学習予算の間に多項式スケーリング則があることを示しており、つまり、与えられたFLOPsの最適なモデルサイズがFLOPsのあるべきべき乗数α> 1に比例するということです。ただし、これらの研究は、モデルサイズの異なる範囲(数百万から数千億のパラメータ)を使用し、αの異なる値(それぞれ約0.7および0.5)を見つけました。自然な疑問は、このスケーリング則が普遍的か、データセットに依存するかどうかです。TinyStoriesのデータセットを使用することで、より小さなモデルとFLOPsで同様の実験を行うことができます。驚くべきことに、多項式スケーリング則の証拠が見つかり、普遍的な現象がある可能性が示唆されています。
TinyStoriesでさまざまなサイズとアーキテクチャのモデルをトレーニングして評価します。各FLOPsの量に対して、可能な組み合わせの中で最も低い検証損失を達成するモデルとトレーニングステップ数を選択します。レイヤーの数を2、4、8、12、および隠れ次元を64、128、256、512、768、1024、2048に変化させます。その結果を図6に示します。データが非常に決定的でないため、点の数が少なくなるかもしれませんが、プロットは多項式依存性を指摘しています。
ヘッドの数の選択。トランスフォーマーのもう1つの設計選択肢は、各レイヤーの注意ヘッドの数です。固定されたモデルの幅と深さが与えられた場合、ヘッドの数がモデルの性能にどのように影響するかは明らかではありません。図24に示す結果は、ヘッドの数が少ない領域では、すべてのメトリックでモデルの性能を向上させることを示唆しています。
7. 関連研究
生成言語モデル(LM)は、テキスト要約、対話生成、物語の完結など、様々な自然言語処理タスクで印象的な成果を収めています。しかし、これらのモデルのほとんどは非常に大きく、数億、あるいは数百億のパラメータを持っているため、訓練、推論、展開に重大な課題があります。例えば、最大のLMの1つであるGPT-3 [4]は1750億のパラメータを持ち、訓練には数百ペタフロップの計算能力が必要です。1250万のパラメータを持つGPT-2 smallなどの小さなモデルは、大規模なコーパスでの事前トレーニングにもかかわらず、わずか数語を超える明確で一貫した文を生成することができません[23]。
大規模なLMを小さくするためのいくつかの手法が提案されています。知識蒸留[10、2]、プルーニング[8]、量子化[13]などです。しかし、これらの手法は、GPTのような自己回帰言語生成に向けられたモデル[26]よりも、マスクされた言語モデリングや下流の分類タスクに向けられたBERTのようなモデル[25、28]に対して効果的です。
生成言語モデルにとってもう一つの課題は、出力の評価です。ラベル付きデータで下流タスクを微調整し、評価できるBERTのようなモデルとは異なり、GPTのようなモデルは「自然言語を話し、理解する能力」をどの程度備えているかを測定するのがより困難です。LAMBADA [22]、CLOZE [29]、TriviaQA [15]、Winograd Schema Challenge [17]などの既存の生成言語モデルのベンチマークは、モデルが答えとして一語または短いフレーズを生成することを要求するため、自然言語の豊かさや多様性を捉えることができません。また、これらのベンチマークは、データセットのサイズや品質、答えの曖昧さや主観性、人間の評価の欠如によって制限されることがよくあります。BigBench [27]のようなより大きく多様なデータセットは、SLMにはあまりにも複雑すぎます。WikiSQL [33]などの他のベンチマークは、より構造化された出力形式を持つため、評価は容易ですが、自然言語生成の代表的なものではありません。
我々の研究は、トランスフォーマーモデルとその学習プロセスの理論的分析にも役立ちます。既存の理論的研究のほとんどは、複数のブロックを持つモデルよりも解析が容易な1つのトランスフォーマーブロックを持つモデルに焦点を当てています。例えば、Voitaら[30]は、1つのトランスフォーマーブロックが自己注意レイヤーの位置によって異なる言語的タスクを実行することができることを示しました。Liら[19]はトピックモデルをエンコードすることができることを示し、Jelassiら[14]は1つのトランスフォーマーブロックがパッチの関連性をエンコードすることができることを示しました。私たちの研究は、1つのトランスフォーマーブロックでも多様で一貫したストーリーを生成することができることを実証し、トランスフォーマーアーキテクチャが少数のパラメータとレイヤーでも強力な表現力を持つことを示唆しています。
8. 結論
この研究では、GPT-3.5とGPT-4によって生成された、通常3〜4歳の子供が理解できる単語だけを含む短編小説の合成データセットであるTinyStoriesを紹介しました。TinyStoriesは、最新のモデルよりもはるかに小さいが、流暢で一貫性があり、複数の段落を持ち、多様性があり、ほぼ完璧な文法を持ち、推論能力を示す小さな言語モデル(SLM)のトレーニングと評価に使用できることを示しました。
インターネット上の巨大で多様な言語コーパスでトレーニングされた大規模なモデルは非常に印象的な能力を示しますが、そのデータセットは言語の複雑な側面を捉えるにはSLMにとって大きすぎるようです。TinyStoriesによって、モデルとデータセットの両方のサイズに関してはるかに小さなスケールで、LMにおける一貫したテキスト生成、推論、指示の遵守などの能力の出現を観察し、研究することができると主張しました。データセットでSLMをトレーニングすることで、幅と深さのトレードオフなどのLLMと類似した多くの振る舞いも観察されました。さらに、トレーニングされたSLMはより高い解釈可能性を持ち、ストーリーを生成し理解する方法を理解するためにその注意力と活性化パターンを視覚化および分析することができることを示しました。
TinyStoriesでトレーニングされたモデルが、データセットのテキストの一部を単にコピーするのではなく、本当に新しいストーリーを生成できることを示しました。ただし、私たちのモデルの「創造性」の真の範囲を評価すること、およびモデルが生成するストーリーの「理解」(もちろん非常に低いレベルで)を反映しているか、単にテンプレートマッチングであり、合理的な継続を作成することを評価することは依然として課題です。このデータセットが言語モデルの創造性の程度に関する洞察を得るために将来的に使用されることを期待しています。
さらに、GPT-4を使用して、モデルが学生によって書かれた物語のように評価されるように、言語モデルの評価のための新しいパラダイムを紹介しました。この新しいパラダイムは、モデルの出力が非常に構造化されていることを要求する標準的なベンチマークの欠点を克服し、モデルの多次元スコアを提供するため、異なる能力のスコアを提供します。このパラダイムはTinyStories以上に有用であると考えています。
最後に、生成ネットワークの知的能力における幅と深さの役割についての初期の発見を紹介しました。幅は事実上の知識を捉えるために重要であり、深さは文脈追跡により重要であることを示唆しています。さらに、文法的および構文的な能力が出現するのは、一貫したテキストを生成する能力よりも早く、それが創造的と考えられるコンテンツを生成する能力よりも早く出現することを示唆しています。これらの初期の発見は示唆的であるだけであり、主な焦点ではありませんでしたが、私たちのデータセットと評価パラダイムが、生成モデルのさまざまな言語能力の出現と評価のより細かい分析を可能にする方法を示しています。
私たちは、TinyStoriesが低リソースや特定の領域向けのLMの開発、分析、研究を促進し、LMにおける言語能力の出現に光を当てることができることを望んでいます。この研究から生じる一般的な質問は、洗練されたデータセットの合成が、実用的な用途のネットワークのトレーニングに有益であるかどうかです。たとえば、仮想的なコールの大規模なデータセットを合成して、顧客サービスチャットボットをトレーニングすることができるかもしれません。