RedditでDeepSeek v3.2における"Interleaved Thinking"(反芻思考)の採用が話題になっていたので、簡単に調べてみました。 https://www.reddit.com/r/LocalLLaMA/comments/1pbal3o/finally_deepseek_supports_interleave_thinking/
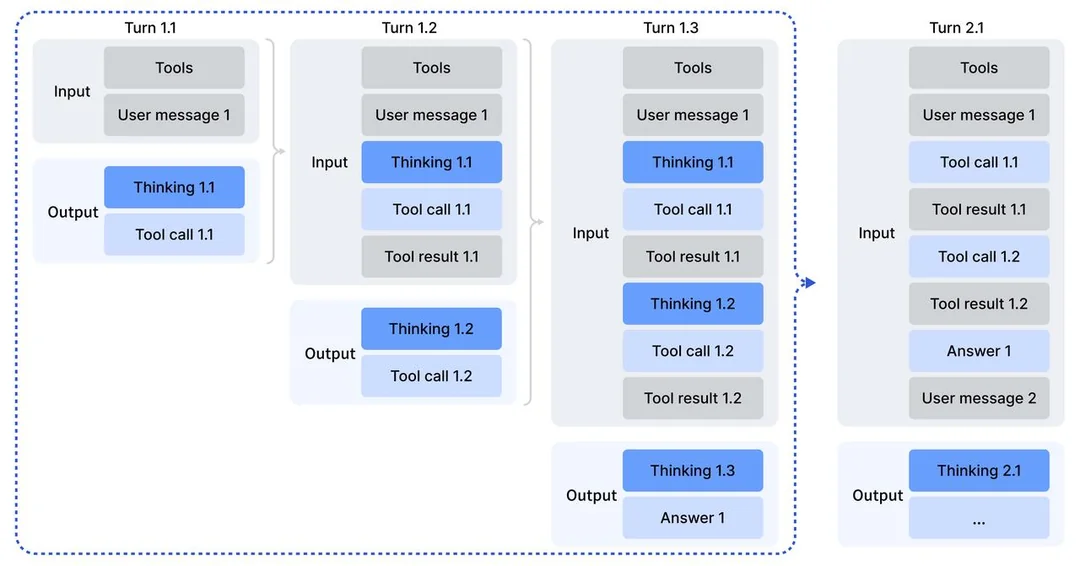
冒頭の図はDeepSeek v3.2の技術レポートに掲載されている説明です。検索・コード実行などのTool Callとその結果分析を繰り返す間は過去のターンの思考内容(Thinking)を保持し続け、次のユーザーメッセージが入力されたタイミングでまとめて削除する、というコンテキスト管理手法で、これを巷では"Interleaved Thinking"と呼ぶそうです。
ChatGPTのo1やDeepSeek R1など初期の思考(CoT)モデルでは、1回のユーザーメッセージに対してThinkingとTool Callを何度も繰り返すことを想定しておらず、Tool Callの結果を得るたびに直前の思考内容を逐一破棄するようなコンテキスト管理になっていました。長い思考をそのまま残すと有限のコンテキストを圧迫するため、できるだけ圧縮したい動機付けがあったためです。
ところが、多段階のTool Callを前提にしたChatGPTのo3においては思考内容を保持し続けるタイプの運用が導入され、この手法を踏襲したClaude Codeがこの手法を"Interleaved Thinking"と命名して概念化しました。"Interleaved Thinking"はコーディングエージェント(コードの実行→結果の検証→修正したコードの実行→結果の検証...を繰り返す)において高い有効性を示すため、Kimi K2 Thinking や MiniMax M2 など中国勢が追随する流れが生まれ、今回 DeepSeek v3.2 でも採用に至った、という経緯のようです。
今のところ、オープン勢における"Interleaved Thinking"の採用はコーディングに焦点を当てたトレーニングを行っている一部のLLMに限られている様子。複数のTool Callを組み込むと学習時のコンテキストが膨むので計算資源を圧迫するという問題もあるのかもしれません。
"Interleaved Thinking"による精度向上については、上述のRedditポストで紹介されている MiniMax のブログで概説されています。思考内容を逐一消去してしまうと同じエラーを繰り返しやすくなるので、最終出力を得るまでは保持し続けるべき、という趣旨のようです。 https://www.minimax.io/news/why-is-interleaved-thinking-important-for-m2
ちなみにDeepSeek v3.2の技術レポートでは具体的に以下のように述べられていて、"Interleaved Thinking"に対応していないフレームワークではそもそも「非思考モデル」を使ったほうがよい(CoTプロセスは、フレームワーク側に実装されている「コードの実行→結果の検証」のループ機構に従ったほうがよい)と推奨されています。
3.2. Thinking in Tool-Use / 3.2.1. Thinking Context Management DeepSeek-R1 has demonstrated that incorporating a thinking process can significantly enhance a model’s ability to solve complex problems. Building on this insight, we aim to integrate thinking capabilities into tool-calling scenarios. We observed that replicating DeepSeek-R1’s strategy—discarding reasoning content upon the arrival of the second round of messages—results in significant token inefficiency. This approach forces the model to redundantly re-reason through the entire problem for each subsequent tool call. To mitigate this, we developed a context management strictly tailored for tool-calling scenarios as shown in Fig 4:
• Historical reasoning content is discarded only when a new user message is introduced to the conversation. If only tool-related messages (e.g., tool outputs) are appended, the reasoning content is retained throughout the interaction.
• When reasoning traces are removed, the history of tool calls and their results remains preserved in the context.
Notably, certain agent frameworks, such as Roo Code or Terminus, simulate tool interactions via user messages. These frameworks may not fully benefit from our enhanced reasoning persistence due to the context management rules outlined above. Therefore, we recommend utilizing non-thinking models for optimal performance with such architectures.
(和訳)DeepSeek-R1は、思考プロセスを組み込むことで、モデルが複雑な問題を解決する能力を大幅に向上させられることを実証しました。この洞察に基づき、我々は思考能力をツール呼び出しのシナリオに統合することを目指しています。 我々は、DeepSeek-R1の戦略(2ラウンド目のメッセージが到着した時点で推論内容を破棄すること)をそのまま模倣すると、著しいトークンの非効率性を招くことを確認しました。このアプローチでは、後続のツール呼び出しのたびに、モデルが問題全体に対して冗長な再推論を行うことを強いられます。これを緩和するために、図に示すような、ツール呼び出しシナリオに厳密に特化したコンテキスト管理を開発しました:
・過去の推論内容は、新しいユーザーメッセージが会話に導入された場合にのみ破棄されます。ツール関連のメッセージ(例:ツールの出力)のみが追加される場合、推論内容は対話を通して保持されます。
・推論トレースが削除される際も、ツール呼び出しとその結果の履歴はコンテキスト内に保存されたままとなります。
特に、Roo CodeやTerminusなどの特定のエージェントフレームワークは、ユーザーメッセージを介してツールとのやり取りをシミュレートします。これらのフレームワークでは、上述のコンテキスト管理ルールによって強化された推論保持機能の恩恵を十分に受けられない可能性があります。そのため、そのようなアーキテクチャでは最適なパフォーマンスを得るために、非思考モデル(non-thinking models)を利用することを推奨します。




