- IBMが「ibm/merlinite-7b」というMistral 7Bベースのファインチューンモデルを公開し、同時にそのファインチューン手法に関するarXiv論文を投稿しています(「LAB: チャットボットのための大規模アライメント」)。
概要
本研究では、大規模言語モデル(LLM)学習の命令チューニング段階におけるスケーラビリティの課題を克服するために設計された新しい方法論であるLAB(Large-scale Alignment for chatBots)を紹介します。分類に基づいた合成データ生成プロセスと多段階のチューニングフレームワークを活用することで、LABは高価な人間のアノテーションやGPT-4のような独自のモデルへの依存を大幅に削減します。我々は、LABで訓練されたモデルが、従来の人間によるアノテーションやGPT-4で生成された合成データで訓練されたモデルと比較して、いくつかのベンチマークで競争力のある性能を達成できることを実証します。このように、破壊的な忘却の欠点なしに、LLMの能力と命令追従動作を強化するためのスケーラブルで費用対効果の高いソリューションを提供することで、広範なアプリケーションのためのLLMの効率的な訓練に一歩前進をもたらします。
メモ
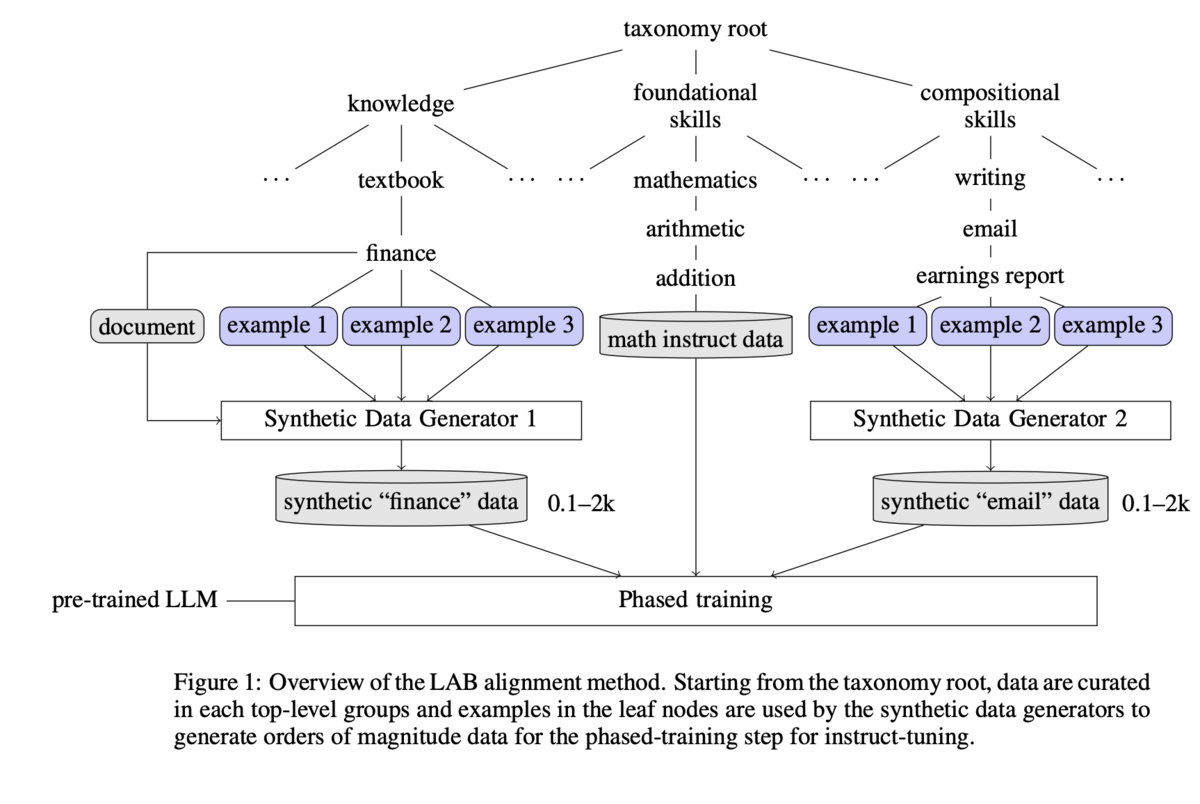
- データセット生成について
- 興味をひかれたのは「多段階のファインチューニング」を採用している点です。
- 1)知識チューニング(短文)→2)知識チューニング(長文)+基礎スキル(計算など)→3)構成スキル という3つの段階で追加学習し、それぞれエポック数などを微妙に調整しています。
- さらにモデルの壊滅的忘却(catastrophic forgetting)を防ぐために、"Replay buffer"として「前段階での学習を繰り返したあとで、現段階の学習を開始する」という手順を踏んでいるとのことです。
