【LLM論文を読む】大規模言語モデルの知識編集(Knowledge Editing)に関するサーベイ
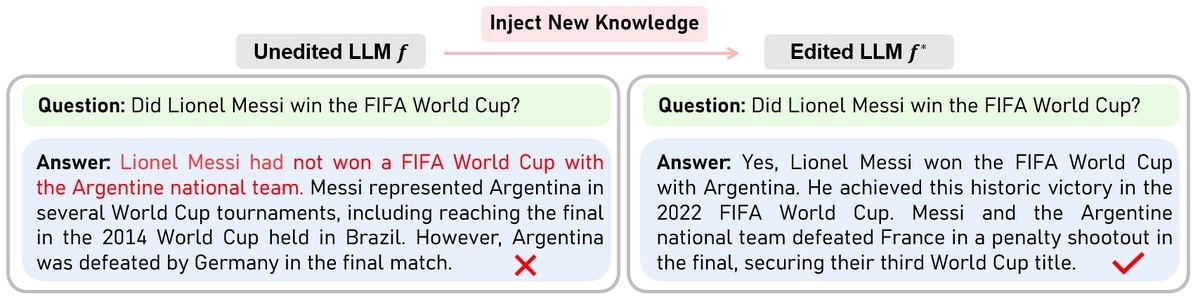
- LLMの知識編集(Knowledge Editing)のあらましをざっくり把握するため、適当なサーベイ論文に目を通してみたいと思います。
- arXivに上がっている2023年10月のバージニア大学の研究者による論文『大規模言語モデルの知識編集に関するサーベイ(Knowledge Editing for Large Language Models: A Survey)』です。
概要
大規模言語モデル(LLM)は、その膨大な知識と推論能力に基づいてテキストを理解、分析、生成する驚くべき能力により、近年、学術界と産業界の両方に変革をもたらした。とはいえ、LLMの大きな欠点のひとつは、前例のない量のパラメータがあるため、事前学習にかなりの計算コストがかかることである。この欠点は、事前学習済みモデルに新しい知識を頻繁に導入する必要がある場合に悪化する。そのため、事前学習されたLLMを更新する効果的で効率的な手法を開発することが不可欠である。従来の手法では、直接微調整を行うことで、事前に訓練されたLLMに新しい知識を組み込む。しかし、素朴にLLMを再トレーニングすることは、計算量が多く、モデル更新に無関係な貴重な事前トレーニング知識を退化させる危険性がある。近年、知識ベースモデル編集(KME)が注目されており、これは、他の無関係な知識に悪影響を与えることなく、特定の知識を取り入れるためにLLMを正確に修正することを目的としている。このサーベイでは、KMEの分野における最近の進歩の包括的かつ詳細な概観を提供することを目的とする。まず、様々なKME戦略を包含するKMEの一般的な定式化を紹介する。その後、新しい知識がどのように事前訓練されたLLMに導入されるかに基づくKME手法の革新的な分類法を提供し、以下の手法の主要な洞察、利点、および限界を分析しながら、既存のKME戦略を調査する。さらに、KMEの代表的なメトリクス、データセット、アプリケーションを紹介する。最後に、KMEの実用性と残された課題に関する詳細な分析を行い、この分野のさらなる進歩のための有望な研究の方向性を提案する。
メモ
- 微調整(ファインチューン)による知識更新には以下のよう問題があり、実用性に難がある。
- 知識編集(KME)では、更新知識とは無関係な他の事前学習済みの知識に悪影響を与えることなく、特定の知識を更新することを目的としている。
- KMEによる知識更新は、"Who is the president of the USA? "の答えを "Trump "から "Biden "に修正するような編集として一般的に定式化される。
- 具体的には、1)事前に訓練されたモデルに補助ネットワーク(またはパラメータセット)を導入する、
- 2)新しい知識を格納するために(部分的な)パラメータを更新することにより、モデル出力を修正する。
- これらの戦略により、新しい知識をメモリに格納したり、更新のためにモデルパラメータに配置したりすることによって知識をモデルに正確に注入する。
- さらに、更新プロセスを抑制するために明示的な損失を導入し、編集されたモデルが、変更されていない知識に対して一貫した振る舞いを維持する手法もある。
- これらの利点により、KMEは明示的なモデルの再学習を行うことなく、常に新しい知識でLLMを更新する効率的な方法を提供する。
- KMEの効果を測定するにあたっては、正確性(Accuracy)に加えて、以下の4つの観点が重要になる。
- 局所性/Locailty:モデルの編集が、他の無関係な入力の出力に意図せず影響を与えないこと。たとえば、米国大統領に関する編集が更新されたとき、モデルが英国の首相に関する知識を変更してはいけない。
- 一般性/Generality:編集されたモデルが、その知識に関する広範囲の関連入力に一般化できること。たとえば、米国大統領に関して知識更新された場合、大統領の配偶者の質問に対する答えもそれに応じて変更される必要がある。
- 保持性/Retainability:複数回の連続した編集の後でも、編集されたモデルの望ましい特性を保持できること。常に変化する情報が存在する中で、チャットモデルを頻繁に更新する場合がある(つまり逐次編集)。
- スケール性/Scalability:一度に多くの更新知識を取り込めること。最近はLLMの特定のパラメータに複数の新しい知識を注入することができるいくつかの研究が登場している。
- KMEの主な手法は、1)外部記憶と接続する手法、2)モデルの全般的最適化を行う手法(特殊な方法による微調整)、3)局所的な修正を施す手法の3つに大別される。

- 1)外部記憶ベースの手法:外部メモリを活用し、事前に訓練された重みを変更することなく、新しい知識を編集のために保存する。新しい知識を外部パラメータに保存することで、モデルの本体構造に影響を及ぼすことなく知識を編集できるが、更新する知識量によってはストレージ容量が大きくなる欠点がある。
- 2)全般的最適化(Global Optimization)手法:新しい知識のガイダンスによる最適化を通じて、新しい知識を事前に訓練されたLLMに汎用的に組み込むことを目指す。要するに通常の微調整(ファインチューン)の改良手法であり、微調整同様に全てのパラメータを更新するため、編集効率が低下する可能性がある。
- 既存の知識に影響が及びにくいように工夫した、制約付きの微調整手法(PPA、F-Learning、Editable Training)。依然として計算コストと不安定性が高い。
- Hyper-Networkを中間モデルとして利用した微調整手法(KE、SLAG、MEND、KGEditor)
- 3)局所的修正(Local Modification)手法:LLMの中から特定の知識に関連するパラメータを探し出し、編集に関連する新しい知識を取り込む。記憶ベースの手法と比較してメモリ効率が大幅に向上し、全般的最適化と比較して計算効率が向上する。

- KMEの抱える主な課題は以下のとおり。
- 局所性と一般性の間のトレードオフ:局所性を重視した手法では、一般性を担保するのが難しくなる傾向がある。
- 大規模な編集:多数の編集、継続的な編集は、モデルの持つ知識の一貫性を損なわせるリスクがあり、パフォーマンスの低下につながる。
- 編集すべき知識の自動検出:現状は人間の作業者が編集すべき知識を特定する必要があり、この労働集約的プロセスを自動化することが期待される。
雑感
- 言語モデルの"微調整"は(その呼び名とは裏腹に)モデルに広範な影響を与えて変質させてしまいます。例えば追加学習済みのチャットモデルを微調整すると、しばしば回答の質が劣化するので、すでに微調整が済んだモデルをさらに追加学習させるのは難度が高いと感じます。
- ローカルLLMをパーソナライズして使いたい場合、おそらく通常の微調整は非効率的な手段であり、一般的にはRAGなどでプロンプトに知識や指示を入れ込む手法が推奨されますが、RAGはRAGで色々な欠点があり難しさがあります。
- 知識編集(KME)はより実用的にモデルを調整できる可能性があり、まだ実験的な手法に留まっている感はありますが、少しずつ試していきたいと思っています。
- ローカルLLMでは、しばしばモデルを量子化して圧縮して使われるので、GGUFなどの量子化に適応できる知識編集手法が必要です。その意味では、外部パラメータに依存する手法などは不向きな感じがします。