TLDR
- AGIEvalは、大学入学試験など人間の受験者を対象にした問題を使ってLLM性能を評価するベンチマークです。
- 米国と中国で行われている各種試験問題を利用しているため、主に英語と中国語における性能が評価されます。
- GPT-4など上位LLMは、人間の受験者と比較しても総合的に高いスコアを示します。ただし、論理的に複雑な問題や専門性の高い問題は人間に比べ苦手にしやすい傾向があります。
- AGIEvalのスコアはChatbot Arenaの一般ユーザー評価(Arena Elo)との相関関係が強いことが指摘されています。
前振り...
- 最近は、大規模言語モデルのベンチマークの中で「LMSYS Chatbot Arena Leaderboard」がコミュニティの強い支持を集めています。
- このベンチマークは、一般ユーザーがLLMの回答を比較評価できるChatbot Arenaのデータに基づくEloレーティングです。
- 既存ベンチマークの実効性が疑問視される中、信頼できる数少ない指標としてOpenAIの@Karpathyさんが言及したことでも話題になりました。
- 既存ベンチマークの主な欠点は、1) 問題が公開されているためベンチマーク汚染(不適切な「テスト対策」)を排除できないこと、2) 機械的な採点/評価方法が使われるため、現実のユースケースでの人間の評価と乖離しやすいこと、などです。
主なLLMベンチマークの相関関係
- さて、そのChatbot Arena Eloを含む主要なLLMベンチマークの相関関係をまとめたツイートがありました。

- この表をみると、Arena Eloと特に相関が高いベンチマークはMT-Bench(0.9)とAGI-Eval(0.9)です。逆にTruthfulQA(0.38)などは相関が弱いです。
- MT-Benchは、Chatbot Arena運営と同じLMSYSが手掛けているので、Arena Eloと高相関なのは分かりやすいです。
- TruthfulQAはOpenAIの作った「回答の安全性」を評価する指標だったと思うので、これが相関していないのも自然な感じがします。Arena Eloと相関が低いからと言ってベンチマークとして無意味なわけでもないはずです。
- なお、この表に含まれるベンチマークのうちHELM LiteやOpenCompassなどは、それ自体がMMLUやARCなどを総合する複合ベンチマークなので留意が必要です。
AGIEvalとは?
- MT-Benchと並んでArena Eloと高い相関を示す「AGI-Eval」というベンチマークをよく知らなかったので調べてみました。
- Microsoftの研究者が提案した「AGI-Eval」は、英語と中国語からなる複合ベンチマークのようです(先ほどの相関表で使われているのは英語のみ)。
- LLM用に設計された問題ではなく、実際に人間が解く試験問題(大学入学共通試験や、法律資格試験など)を使って性能評価を試みるものです。
- 元論文は2023年4月にarxivに投稿されています。現実の人間の知的処理を代替できる「汎用人工知能(AGI)」としての性能を評価するベンチマークとして位置づけたい意図があるようです。
概要(機械翻訳)
人間レベルのタスクに取り組む基礎モデルの一般的な能力を評価することは、汎用人工知能(AGI)の追求において、その開発と応用に不可欠な側面である。人工的なデータセットに依存する従来のベンチマークでは、人間レベルの能力を正確に表現できない可能性がある。本稿で紹介するAGIEvalは、大学入試、法科大学院入学試験、数学コンテスト、弁護士資格試験など、人間中心の標準化試験の文脈で基礎モデルを評価するために特別に設計された新しいベンチマークである。このベンチマークを用いて、GPT-4、ChatGPT、Text-Davinci-003を含むいくつかの最先端の基礎モデルを評価する。印象的なことに、GPT-4はSAT、LSAT、数学の競技において人間の平均的な成績を上回り、SAT数学のテストでは95%の精度を達成し、中国の全国大学入試の英語のテストでは92.5%の精度を達成しました。これは、現代の基礎モデルの並外れた性能を示している。これとは対照的に、GPT-4は複雑な推論や特定の領域知識を必要とする課題では能力が劣ることもわかった。モデルの能力(理解、知識、推論、計算)の包括的な分析により、これらのモデルの長所と限界が明らかになり、一般的な能力を強化するための将来の方向性について貴重な洞察を提供する。人間の認知と意思決定に関連するタスクに集中することで、我々のベンチマークは、実世界のシナリオにおける基礎モデルの性能について、より有意義で強固な評価を提供する。
AGI Evalランキング
- AGI EvalによるLLMのランキングは、OpenCompassのサイトで確認できます。最初に表示されるのは中国語指標を含む総合ランキングなのでご留意ください。
- 英語のみのスコアをみると、GPT-4が抜きん出ているのは他のベンチマークと同じですが、すぐ下にはQwen-72BやYi-34B系など中国のモデルが続いています。
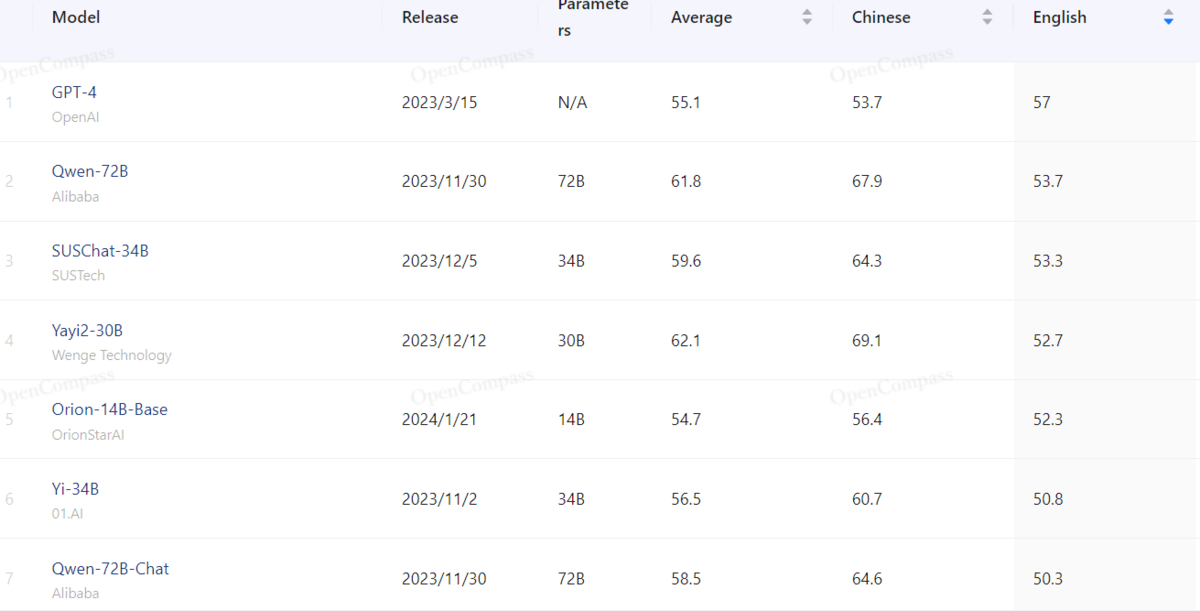
- OpenCompassが中国のサイトで、単純に中国系モデルが多く扱われているという側面もありますが、どうやら中国系モデルは総じてこの種の試験問題を得意としているようです。
- 一方、ローカルLLMの中でArena Eloでのユーザー評価が最も高い「Mixtral 8x7B Instruct」は、AGIEvalでは並み居る中国系モデルの後塵を拝しています。
雑感
- 先日「台湾の大学共通試験(英語)を解かせたらQwen 72BがGPT-4に勝った」という投稿も見かけました。中国系のモデルは、学習プロセスで試験問題系のデータを重視している可能性も十分ありそうです。受験社会だから?
- Qwen-72Bは今のところArena Elo Leaderboardには採用されていません。ただ、AGIEvalでQwen-72Bより下にいるYi-34BがArena Eloではかなり強い(ローカルLLMでMixtral 8x7Bに次いで2番目)ので、Qwen-72Bはそれ以上のレーティングをとれるポテンシャルがあるのかもしれません。
- なお、チャットモデルよりベースモデルのほうがスコアが高いのは、多くのベンチマークで共通して見られる傾向です。選択式・短答式の問題にはシンプルなテキスト補完の方が適しているからだと思います。